
Enterprise Azure Data & AI Platform
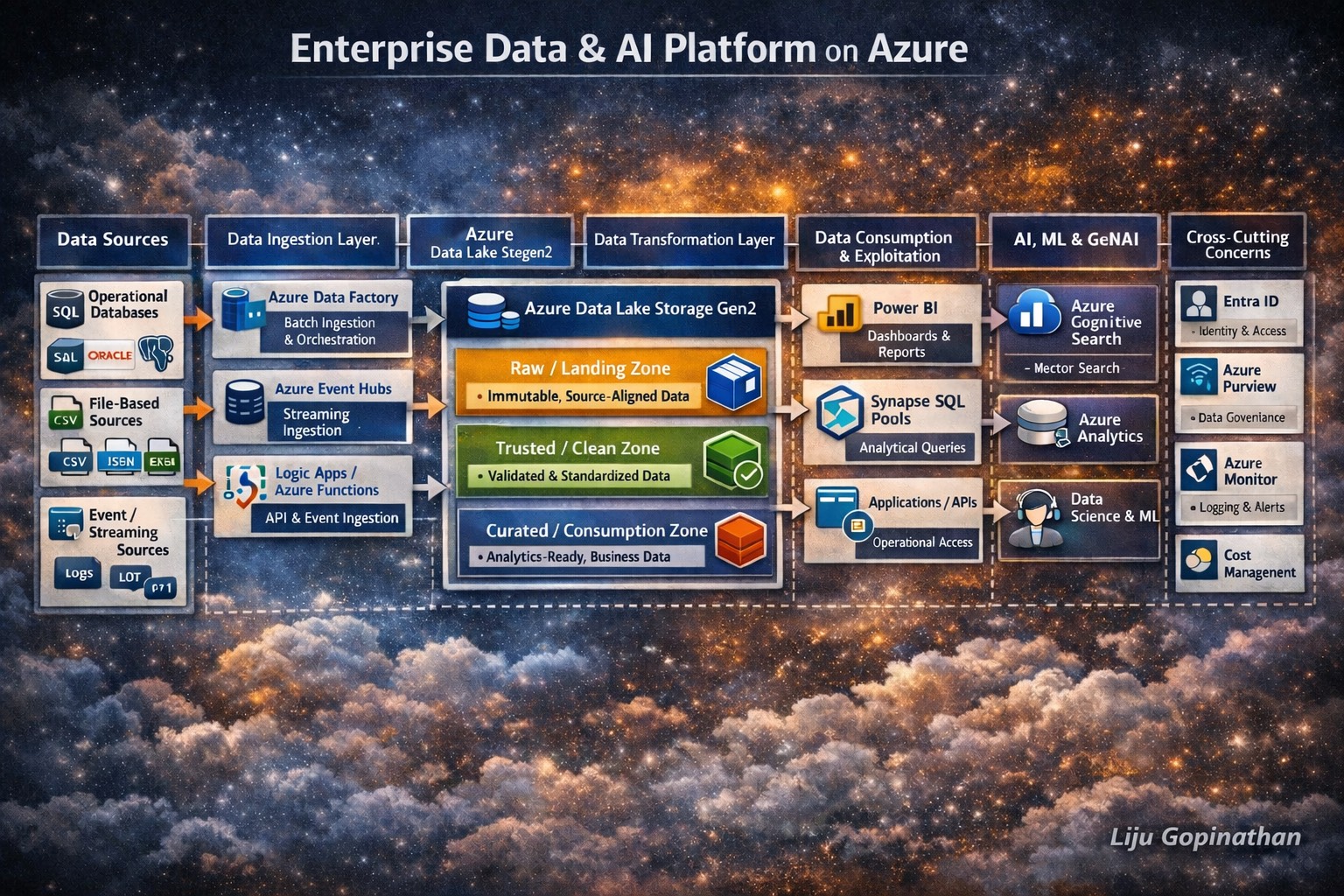
End-to-End Data Lifecycle Architecture Using Azure Native Services
Modern enterprises require more than isolated analytics or AI solutions. They need a cohesive, governed and scalable data platform that supports the entire data lifecycle from ingestion to transformation, analytics, machine learning and Generative AI.
The architecture illustrated above represents a holistic Enterprise Data & AI Platform built entirely using Azure native services. It demonstrates how data flows securely and reliably from multiple source systems, through structured processing layers and ultimately into consumption and AI/GenAI workloads.
This design reflects real-world enterprise patterns, aligned with regulated environments, cloud best practices and modern data platform principles.
Architectural Principles
This platform is designed around the following core principles:
- Separation of concerns across ingestion, storage, processing, and consumption
- Lakehouse-style architecture using Azure Data Lake as the backbone
- ELT-first approach (Extract → Load → Transform)
- Governance and security embedded at every layer
- AI and GenAI readiness by design, not as an afterthought
- Azure-native services only, ensuring long-term support and integration
1. Data Sources Layer
The data lifecycle begins with diverse enterprise data sources, which typically include:
- Operational DatabasesExamples: SQL Server, Oracle, PostgreSQLThese systems generate transactional and reference data critical for analytics and AI.
- File-Based SourcesFormats such as CSV, JSON, Excel, Parquet originating from internal systems, partners, or legacy platforms.
- SaaS & Application DataData exposed via REST APIs from CRM, ERP, ticketing, or third-party platforms.
- Event & Streaming SourcesApplication events, telemetry, logs, and IoT data produced continuously in near real time.
This layer is intentionally technology-agnostic, representing any system capable of producing data.
2. Data Ingestion Layer (Azure Native)
The ingestion layer is responsible for reliably moving data into Azure, without applying heavy business logic.
Azure Data Factory (ADF)
Azure Data Factory acts as the primary batch ingestion and orchestration service.
Key responsibilities:
- Scheduled and on-demand ingestion
- Source-to-lake data movement
- Pipeline orchestration and dependency management
- Metadata-driven ingestion patterns
ADF is deliberately used for data movement and orchestration, not complex transformations.
Azure Event Hubs
Azure Event Hubs supports streaming and real-time ingestion.
Typical use cases:
- Application logs
- Clickstream data
- IoT telemetry
- Event-driven business workflows
Event data is treated as a first-class citizen, landing in the same lake structure as batch data to ensure unified processing.
Azure Logic Apps & Azure Functions
These services enable API-based and event-driven ingestion.
They are used for:
- REST API integrations
- SaaS data ingestion
- Lightweight preprocessing
- Handling authentication, retries, and throttling
This pattern allows ingestion to remain loosely coupled and extensible.
3. Landing Zone – Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 (ADLS Gen2) forms the central backbone of the platform.
It is organised into logical zones, each with a clear purpose.
Raw / Landing Zone
- Stores data exactly as received
- Immutable and append-only
- Preserves original structure and semantics
- Enables replay, audit, and lineage
No analytics or AI workloads directly access this zone.
Trusted / Clean Zone
- Basic data quality checks
- Schema validation and standardisation
- Removal of corrupt or invalid records
- Normalisation of formats
This zone represents technically reliable data, but not yet business-optimised.
Curated / Consumption Zone
- Business-aligned datasets
- Optimised storage formats (e.g., Parquet, Delta)
- Designed for analytics, ML, and GenAI consumption
- Domain- or subject-area oriented
This is the only zone exposed to downstream consumers.
4. Data Transformation & Processing Layer
Transformation is performed after data is safely landed, following an ELT model.
Azure Databricks
Azure Databricks is the primary large-scale transformation and feature engineering engine.
Responsibilities:
- Data cleansing and enrichment
- Complex joins and aggregations
- Incremental processing
- Feature creation for ML workloads
- Delta Lake-based reliability and versioning
Databricks supports both batch and streaming transformations, ensuring consistency across data types.
Azure Synapse Analytics
Azure Synapse complements Databricks by enabling:
- SQL-based analytical transformations
- Data modelling and serving
- Integration with BI tools
- Analytical views over curated datasets
Synapse acts as the bridge between data engineering and analytics.
5. Data Consumption & Exploitation Layer
Once data is curated, it becomes available for controlled and governed consumption.
Power BI
Used for:
- Enterprise reporting
- Dashboards
- Self-service analytics
Power BI connects only to curated and approved datasets.
Azure Synapse SQL Pools
Provide:
- High-performance analytical querying
- SQL access for analysts and applications
- Consistent semantic models
Applications & APIs
Curated data can be exposed via APIs to:
- Internal applications
- Downstream systems
- Operational reporting tools
Data Science & Advanced Analytics
Data scientists access curated datasets for:
- Exploratory analysis
- Feature experimentation
- Model development
Direct access to raw data is intentionally restricted.
6. AI, ML & Generative AI Enablement
The platform is designed to natively support AI and GenAI workloads.
Azure Machine Learning
Azure Machine Learning manages the full ML lifecycle:
- Training and experimentation
- Feature consumption
- Model registry
- Deployment and monitoring
It consumes governed, curated data, ensuring reproducibility and compliance.
Azure Cognitive Search
Azure Cognitive Search enables:
- Full-text search
- Semantic search
- Vector search for embeddings
It is a key component for Retrieval-Augmented Generation (RAG) patterns.
Azure OpenAI Service
Azure OpenAI provides LLM inference capabilities.
In a RAG pattern:
- Curated documents are indexed in Cognitive Search
- Relevant context is retrieved using vector search
- Context is passed to Azure OpenAI
- Grounded, auditable responses are generated
This ensures:
- Reduced hallucination
- Data boundary enforcement
- Enterprise-grade GenAI usage
7. Security, Governance & Observability (Cross-Cutting)
Security and governance span every layer of the architecture.
Microsoft Entra ID (Azure AD)
- Identity and access management
- Role-based access control (RBAC)
Managed Identities
- Secure service-to-service authentication
- No secrets embedded in code
Microsoft Purview
- Data catalog
- Lineage tracking
- Classification and governance
Azure Monitor & Log Analytics
- End-to-end observability
- Operational monitoring
- Troubleshooting and alerting
Cost Management
- Visibility into data and AI workloads
- Cost optimisation and governance
End-to-End Lifecycle Summary
This architecture illustrates a complete enterprise data lifecycle:
- Ingest data from any source
- Land it safely and immutably
- Transform it through governed layers
- Consume it via analytics and APIs
- Enable AI & GenAI using trusted data
- Secure and govern everything end-to-end
Why This Architecture Matters
This design demonstrates:
- Cloud-native best practices
- AI-first data platform thinking
- Strong governance and compliance
- Scalability and extensibility
- Real-world enterprise applicability
It moves beyond “data pipelines” into a true enterprise data and AI platform.